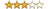|

Post
#1
|
|
|
Grupa: Zarejestrowani Postów: 51 Pomógł: 0 Dołączył: 31.01.2003 Skąd: piękne, czyste, pachnące Katowice Ostrzeżenie: (0%) 
|
to wycinek danych z mojej bazy:
widzicie tutaj informacje o pytaniach przesyłanych przez użytkowników mojej stronki. Ta tabela prezentuje odpowiedzi na te pytania, np. w pytaniu 306 kontakt z użytkownikiem pojawił się 8 razy (8 rekordów w bazie). potrzebuje dowiedzieć się, jaki był czas odpowiedzi po wysłaniu pytania przez użytkownika. W pyt. 306 kontakt użytkonika rozpoczął się 12.07 o godz. 11:06:26. O 11:24:11 dostał odpowiedz. Potrzebuję obliczyć różnicę czasu między tymi rekordami. Czyli pozostałe 6 rekordów dla tego pytania mnie nie interesuje (ważna jest pierwsza odpowiedz na pytanie). Problem polega na tym, że takich pytań mam w bazie kilkaset i chcę to policzyć dla wszystkich. Siedzę nad tym i przyznam, że nie mam pomysłu. Pewnie da się to jakoś zrobić przez podzapytania, ale w tym jestem słaby. Może ktoś ma pomysł? z góry dzieki! |
 |
 
|
|
Post
#2
|
|
|
Grupa: Zarejestrowani Postów: 2 064 Pomógł: 1 Dołączył: 22.01.2003 Skąd: Poznań Ostrzeżenie: (0%)
|
Baza jest troche źle zaprojektowana, najlepszym wyjsciem byloby trzymanie daty i czasu w jednym polu jako unix timestamp, co umowliziwa operacje na czasie i dacie przez zwykle operacje arytmetyczne.
W tym przypadku musiałbyś zapewne w zapytaniu złączyć date i czas w jedno pole (tymczasowe), potem rozbić to przy pomocy funkcji daty i czaus mysqla - albo pobrać dane do php i obliczenia wykonywać w php. Pobierasz 2 rekordy, posortowane wg daty ASC, i czasu ASC z limitem 2, nastepnie w pierwszym zamieniasz date i czas na format unix timestamp, tak samo z drugim i odejmujesz. Ten post edytował spenalzo 12.07.2005, 19:44:05 |
|
|
|
|
Post
#3
|
|
|
Grupa: Przyjaciele php.pl Postów: 2 923 Pomógł: 9 Dołączył: 25.10.2004 Skąd: Rzeszów - studia / Warszawa - praca Ostrzeżenie: (0%)
|
Cytat Baza jest troche źle zaprojektowana, najlepszym wyjsciem byloby trzymanie daty i czasu w jednym polu jako unix timestamp, co umowliziwa operacje na czasie i dacie przez zwykle operacje arytmetyczne. Dokladnie o tym samym pomyslalem. Ja bym to zrobil tak: laczysz 2 pola do postaci Timestamp i wyciagasz min i max dla timestatmpa o takim id jakie potrzebujesz (jesli szystkie to musisz pokombinowac z grupowaniem), Jesli bedziesz mial min i max to w nadrzednym zapytaniu zwracasz sobie roznice. |
|
|
|
|
Post
#4
|
|
|
Grupa: Zarejestrowani Postów: 51 Pomógł: 0 Dołączył: 31.01.2003 Skąd: piękne, czyste, pachnące Katowice Ostrzeżenie: (0%)
|
dzięki za podpowiedzi!
problemem nie jest tyle porównanie czasu (z tym sobie poradzę bez problemu w php) tylko z wybraniem dwóch rekordów do porównania. zamiast pobierać wszystkie wpisy dla jedengo pytania, chcę pobrać tylko te dwa które potrzebuję. Chodzi o konkretne zapytanie, którym moge to zrealizować. To zapytanie ma pobierać po dwa rekordy dla wszystkich pytań jakie mam zarejestrowane od razu, tak żebym mógł sobie w php np. policzyć średnią itp. Może ktoś ma pomysł, jak powinno wyglądać zapytanie? |
|
|
|
|
Post
#5
|
|
|
Grupa: Zarejestrowani Postów: 2 064 Pomógł: 1 Dołączył: 22.01.2003 Skąd: Poznań Ostrzeżenie: (0%)
|
Nie da sie raczej zrobić tego jednym zapytaniem - a nawet jeśli to byłoby to niepotrzebne cudowanie. Nalezy pamietac, ze czasami 100 zapytan jest szybciej obsluzonych niz 1 skomplikowane.
Zapytanie 1.
wrzucasz id do jakiejs zmiennej, np. $last_id
Oczywiście, przy załozeniu, ze pole id jest auto increment. Ten post edytował spenalzo 12.07.2005, 23:13:55 |
|
|
|
|
Post
#6
|
|
|
Grupa: Przyjaciele php.pl Postów: 2 923 Pomógł: 9 Dołączył: 25.10.2004 Skąd: Rzeszów - studia / Warszawa - praca Ostrzeżenie: (0%)
|
Cytat Nie da sie raczej zrobić tego jednym zapytaniem - a nawet jeśli to byłoby to niepotrzebne cudowanie. Nalezy pamietac, ze czasami 100 zapytan jest szybciej obsluzonych niz 1 skomplikowane. No nie do konca tak jest, zalezy jak do tego podejdziesz i ile czasu poswiecisz na jego dostrojenie i wtedy sie przekonasz co jest lepsze. Odnosnie tych petli to sa np funkcje, procedury ale to sie tyczy innych baz danych. Tak czy inaczej mozna na wiele sposobow kombinowac i roznie z tym bywa. Mam taka mala uwage do tych Twoich zapytan. Lepiej uzyc max i min bo jest wydajniejsze, wczoraj byl o tym post i kazdy byl za tym. Prosty przyklad 1. Dla pola bez indeksu metoda z order by - sortujesz (btree) - operacja limit metoda z max - wybierasz najwieksza wartosc (chyba szukanie binarne) Porownujac algorytmy 2 sposob jest szybszy. Wariant 2 z indexem na pole data metoda z order by - wartosci posortowane - operacja limit metoda max - odczytanie ostatniej wartosci Tez 2 przyklad jest szybszy. Jesli na dodatek zrobisz z tych zapytan 2 podzapytanie i dasz je jako zbior w FROM to powinienes otrzymac wynik szybciej niz pojedyncze 2 zapytania. Wydaje mi sie ze nie walnolem nigdzie gafy jak by co to poprawcie mnie. (IMG:http://forum.php.pl/style_emoticons/default/smile.gif) |
|
|
|
|

|
Aktualny czas: 23.12.2025 - 17:34 |